---
title:
Чергові нічого не значущі бенчмарки автономних агентів :)
date:
2026-06-12
draft:
false
---
https://github.com/korchasa/flowai-experiments/tree/main/agents-comparison
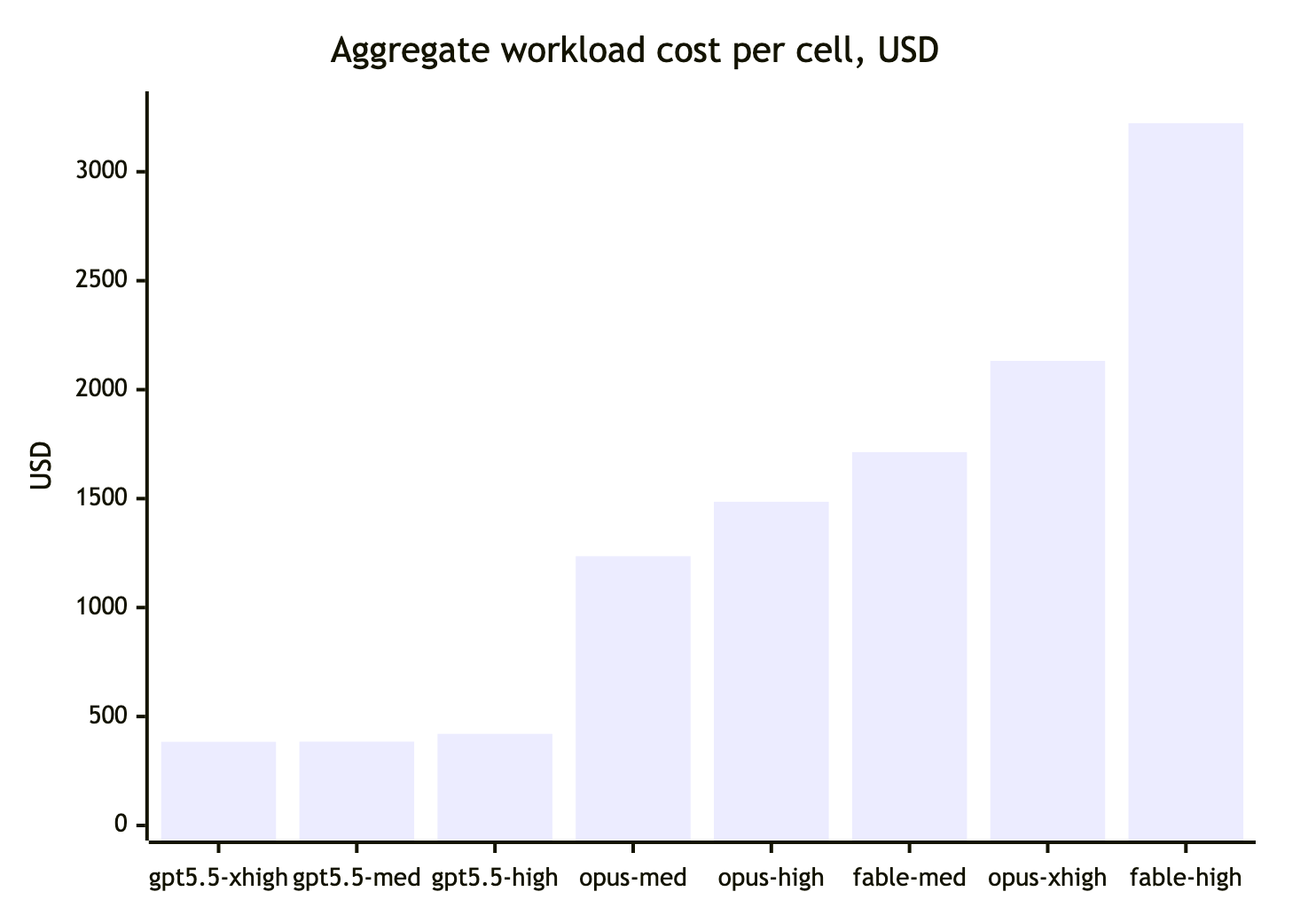
Поганяв на 40% ліміту бенчмарки, наближені до моїх реальних задач, на opus/fable/gpt-5.5 — повністю автономна агентська робота: генерація застосунку з нуля, аудит проєкту і три задачі реалізації різної складності.
Що можна сказати хоч скільки-небудь впевнено:
- fable за якістю результату кращий за opus-4.8 і gpt-5.5. Для себе сформулював гіпотезу fable medium = opus xhigh.
- opus xhigh — несподівано дорогий через занадто довгі роздуми. Іноді дорожчий за fable.
- Зовнішній вигляд — це все ще біль. Усе темно-неоново-однакове.
- На повноцінні тести знадобиться 1-2 тижневих ліміти на claude x20.
Гіпотези:
- Вибір найкращої моделі залежатиме від стадії розвитку проєкту.
- В окремих випадках дорожчі, але якісніші моделі можуть бути виправдані навіть за вартістю на довжині однієї задачі, без урахування технічного боргу.
- Тривалість роздумів понад певний поріг уже не дає приросту якості, а лише збільшує вартість.