---
title:
Очередные ничего не значащие бенчмарки автономных агентов :)
date:
2026-06-12
draft:
false
---
https://github.com/korchasa/flowai-experiments/tree/main/agents-comparison
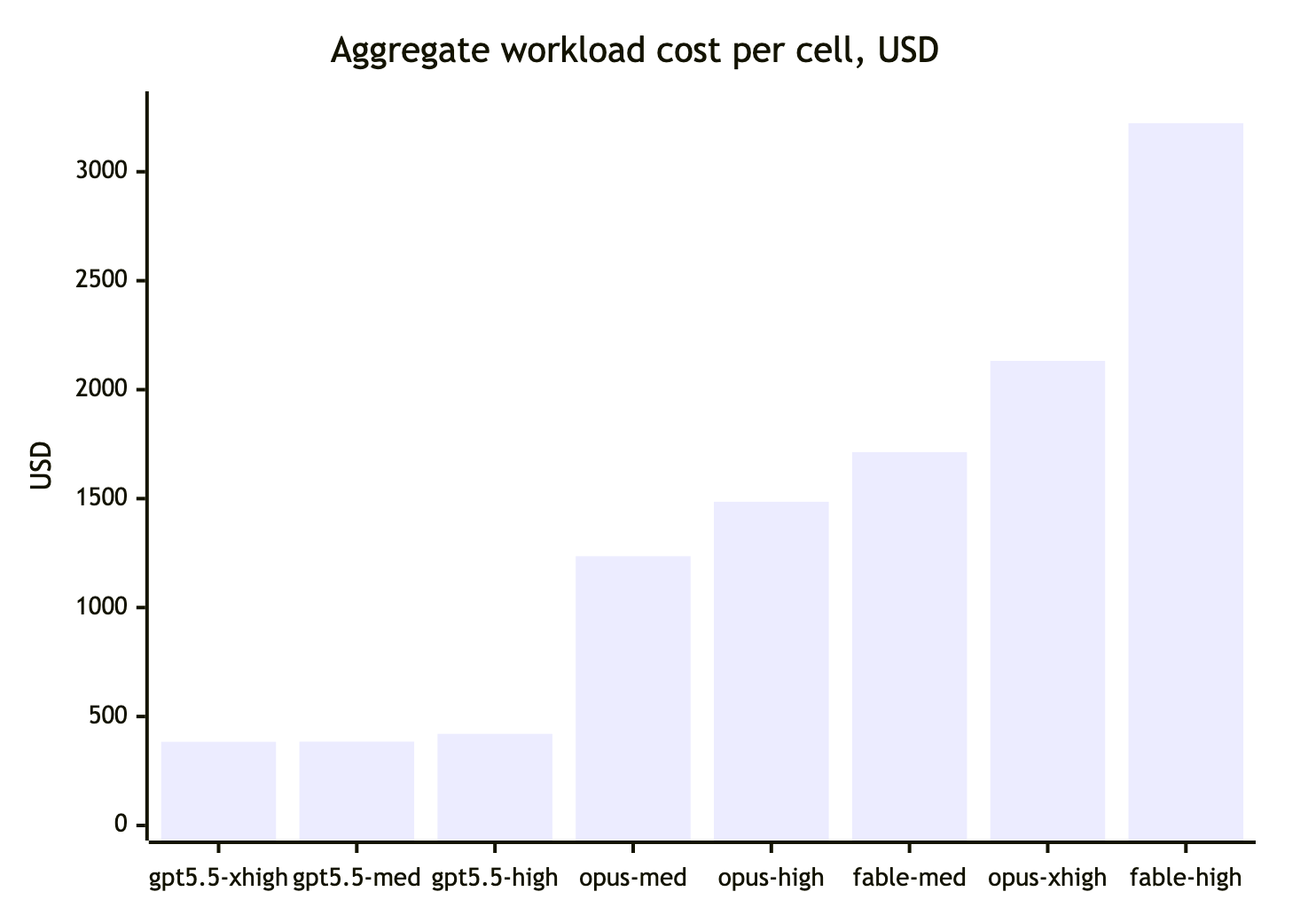
Погонял на 40% лимита бенчмарки, приближенные к моим реальным задачам, на opus/fable/gpt-5.5 — полностью автономная агентская работа: генерация приложения с нуля, аудит проекта и три задачи реализации разной сложности.
Что можно сказать хоть сколько-то уверенно:
- fable по качеству результата лучше opus-4.8 и gpt-5.5. Для себя сформулировал гипотезу fable medium = opus xhigh.
- opus xhigh — неожиданно дорогой из-за слишком долгих размышлений. Иногда дороже fable.
- Внешний вид — это все еще боль. Все темно-неоново-одинаковое.
- На полноценные тесты нужно будет 1-2 недельных лимита на claude x20.
Гипотезы:
- Выбор лучшей модели будет зависеть от стадии развития проекта.
- В отдельных случаях более дорогие, но более качественные модели могут быть оправданы даже по стоимости на длине одной задачи, без учета технического долга.
- Длительность размышлений свыше какого-то порога уже не дает прироста качества, а только увеличивает стоимость.