---
title:
Поредните нищо не значещи бенчмаркове на автономни агенти :)
date:
2026-06-12
draft:
false
---
https://github.com/korchasa/flowai-experiments/tree/main/agents-comparison
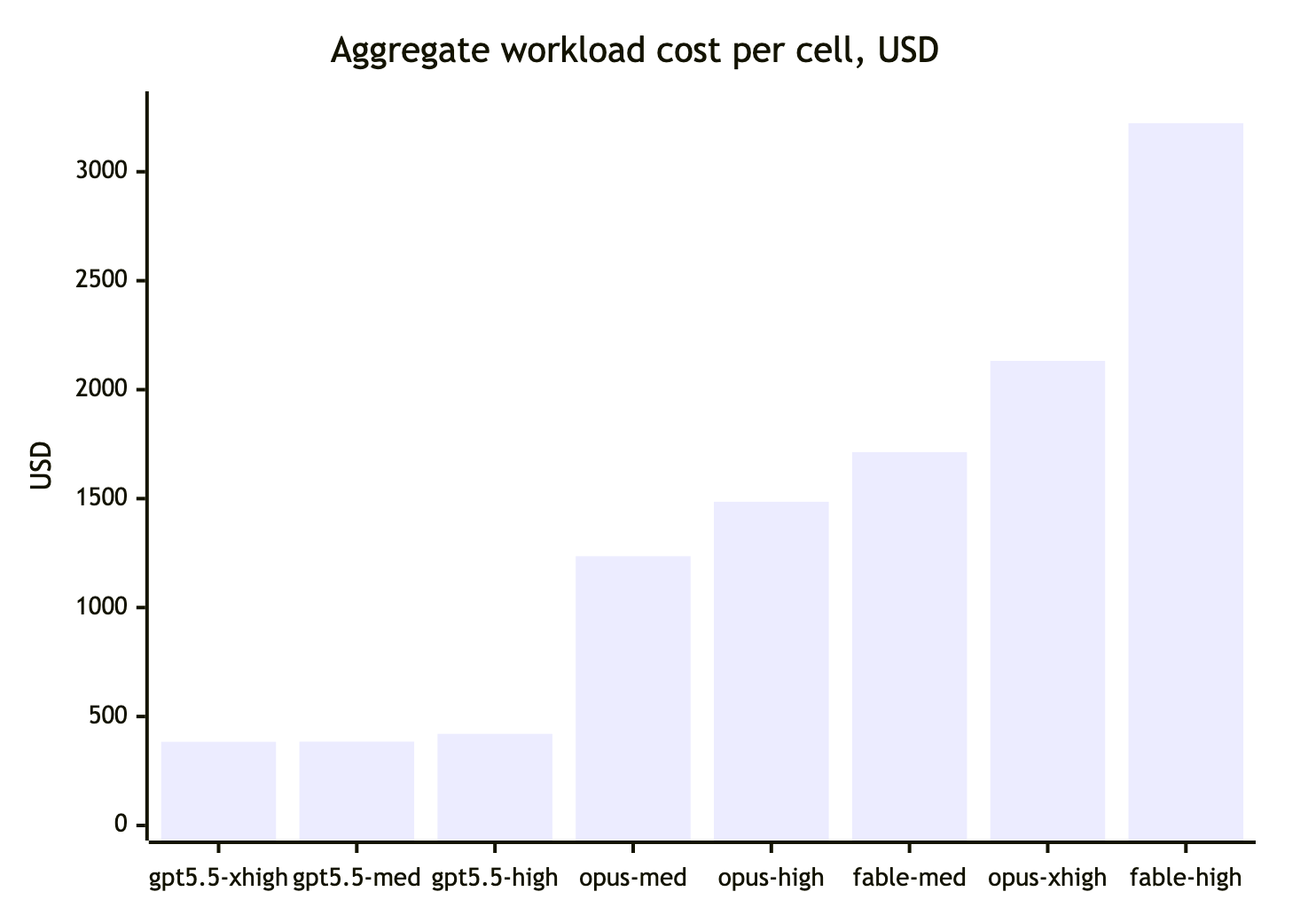
Погоних на 40% от лимита бенчмаркове, близки до моите реални задачи, на opus/fable/gpt-5.5 — напълно автономна агентска работа: генериране на приложение от нулата, одит на проект и три задачи за реализация с различна сложност.
Какво може да се каже поне донякъде уверено:
- fable по качество на резултата е по-добър от opus-4.8 и gpt-5.5. За себе си формулирах хипотезата fable medium = opus xhigh.
- opus xhigh — неочаквано скъп заради твърде дългите разсъждения. Понякога по-скъп от fable.
- Външният вид все още е болка. Всичко е тъмно-неоново-еднакво.
- За пълноценни тестове ще са нужни 1-2 седмични лимита на claude x20.
Хипотези:
- Изборът на най-добрия модел ще зависи от стадия на развитие на проекта.
- В отделни случаи по-скъпите, но по-качествени модели могат да бъдат оправдани дори по стойност в рамките на една задача, без да се отчита техническият дълг.
- Продължителността на разсъжденията над някакъв праг вече не дава прираст в качеството, а само увеличава цената.